WebApp Introduction
Dashboard and side navigation
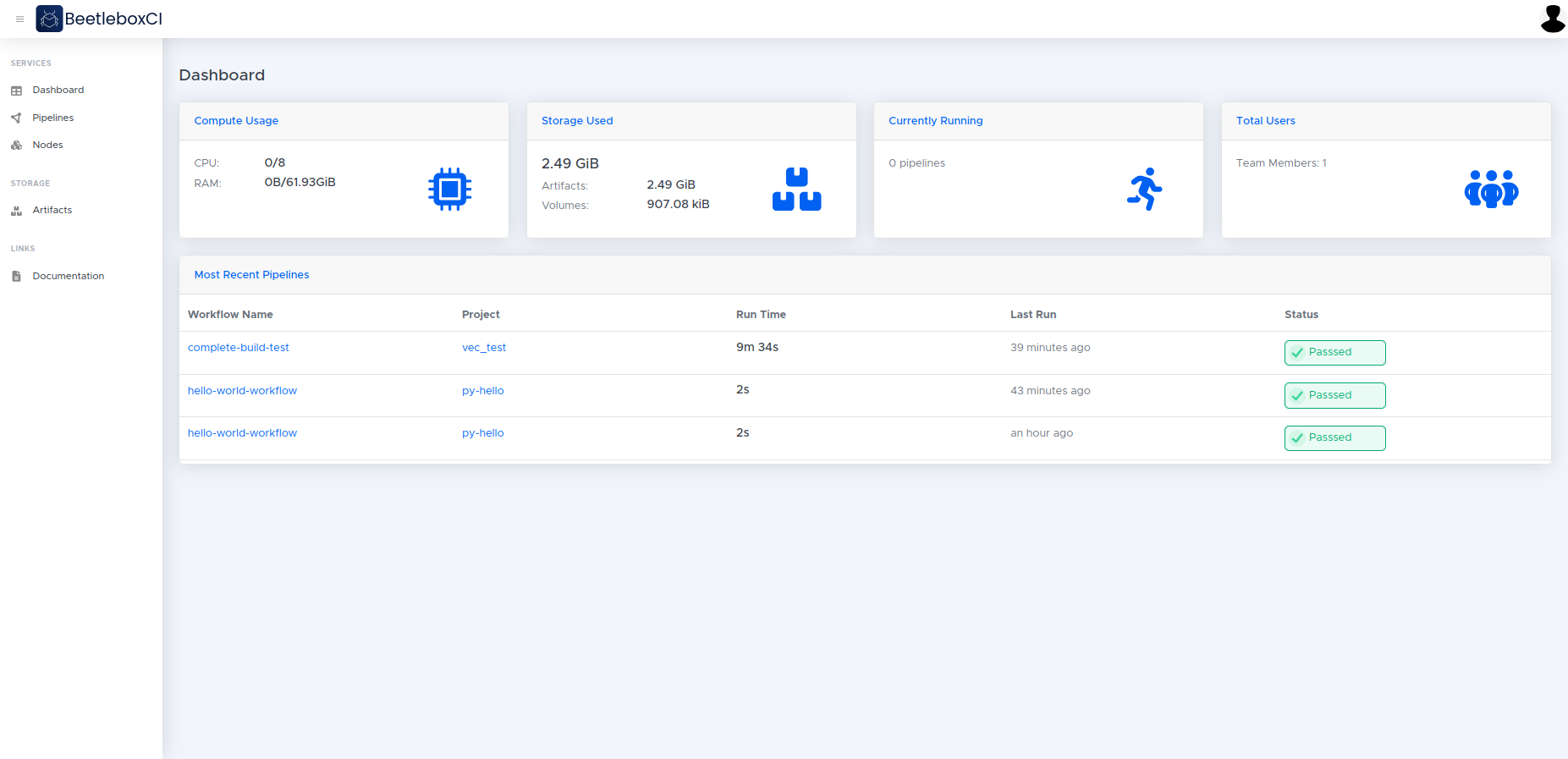
Upon logging in, you will see the Dashboard, showing you the status of pipelines of recently run projects. On the dashboard we will all see useful stats and figures, for example current usage and total team storage used.
The side navigation allows you to visit the following web application pages:
Pipelines: Allows you to see all projects associated with your organization and set up new projects.
Nodes: Shows the machines that are part of the cluster. For the time being, BeetleboxCI supports only single-node clusters.
Devices: Shows the devices that are currently registered with the application.
Artifacts: Files that have been uploaded by a user or generated by a job and is kept after the workflow has completed.
Images: Shows the list of templates that are available to spawn a runner to run jobs.
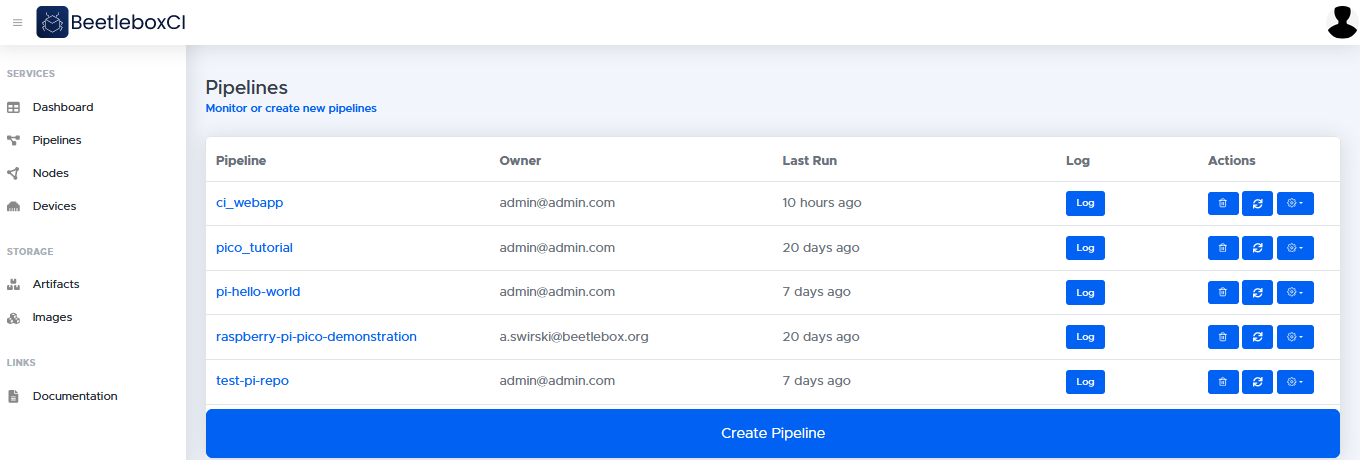
Pipelines
Pipelines associated with your organization will appear on the pipelines page. Setting up a pipeline will add it to your dashboard and pipelines page. Deleting a pipeline will remove it from your dashboard. From this view we can also see a top level log of the pipeline and have the option to delete the pipeline.
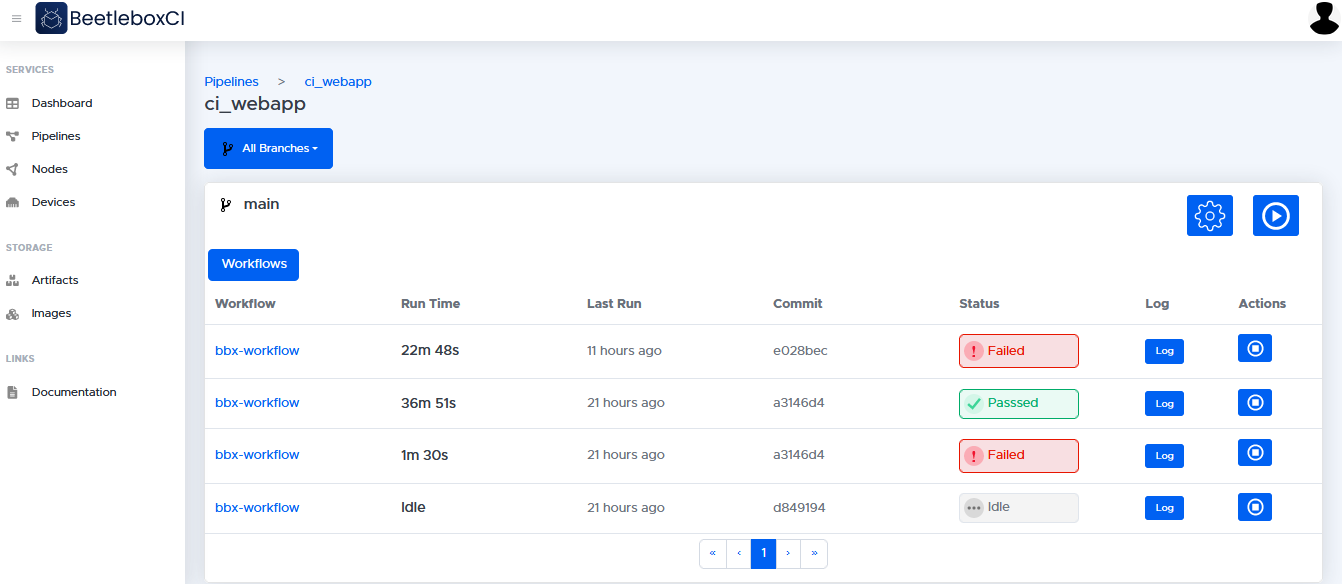
Workflows
Workflows are the building blocks for the project. One more more workflows together will form a pipeline and there may be multiple version control branches (for example a main branch and a develop branch). This page shows the status of the separate workflows and gives a run history. From here we can also view the top level log of the workflow, stop the workflow, see when it was last run and how long it took. Users can also see the git commit ID so this can be traced back to who wrote the code for the last commit.
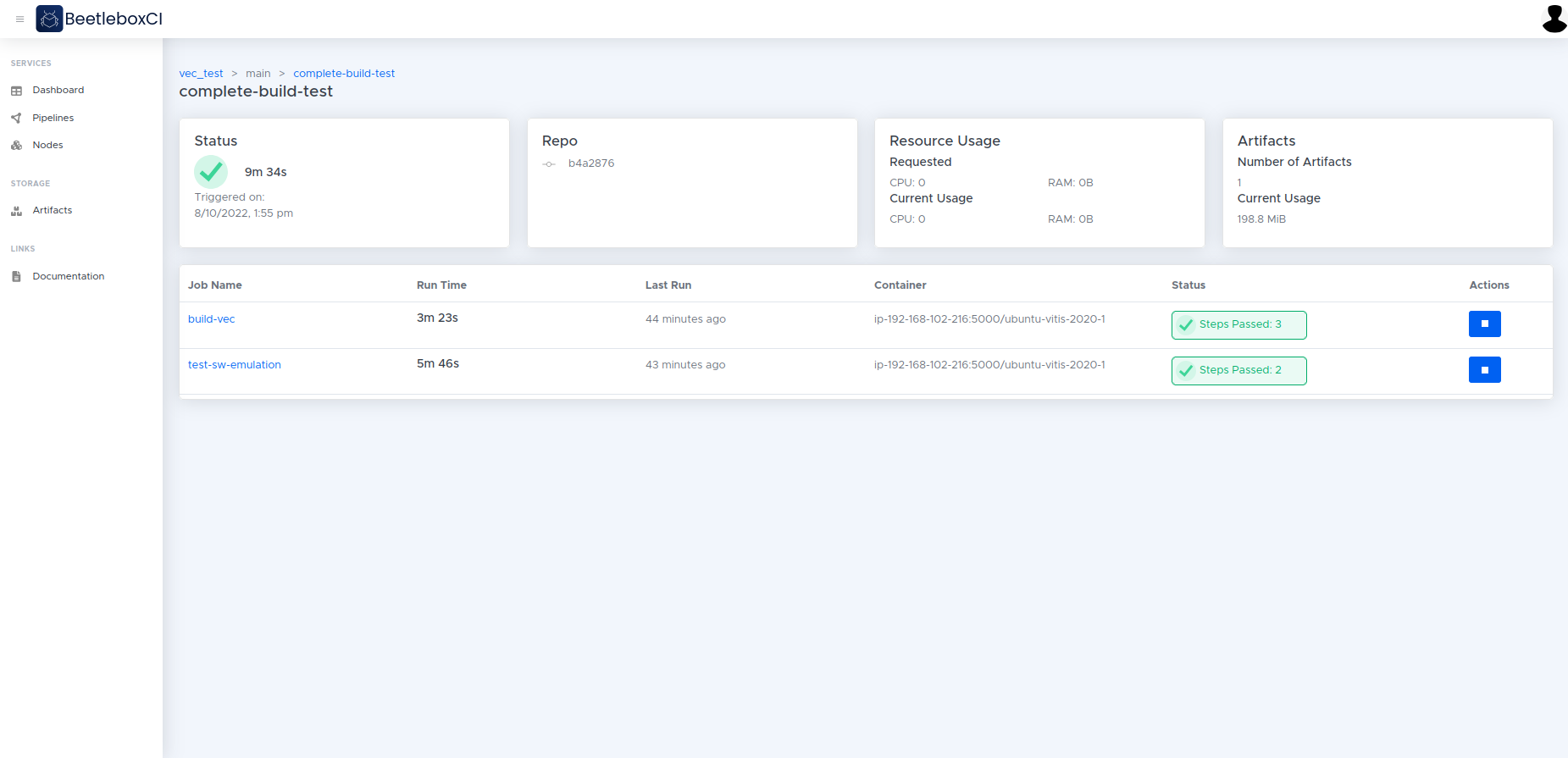
Jobs
Jobs are a distinct set of steps that are to be run as part of the pipeline. They are also used to specify the runner that will be used to execute these tasks. The Jobs page tells the user the progress and status of jobs including when they were run and how long they lasted. We can see the status of the jobs when they were last run and how long they were run for. We also get information about the usage of the jobs and how many artifacts are used.
Inside the job
From the page of an individual job, we can see the steps in the job and we can see the output from these steps by clicking on each step. On this page we also get aditional information about the job, the time taken to run and last time it was run. If the job is currently running we are also provided with its current staus and the resource usage.
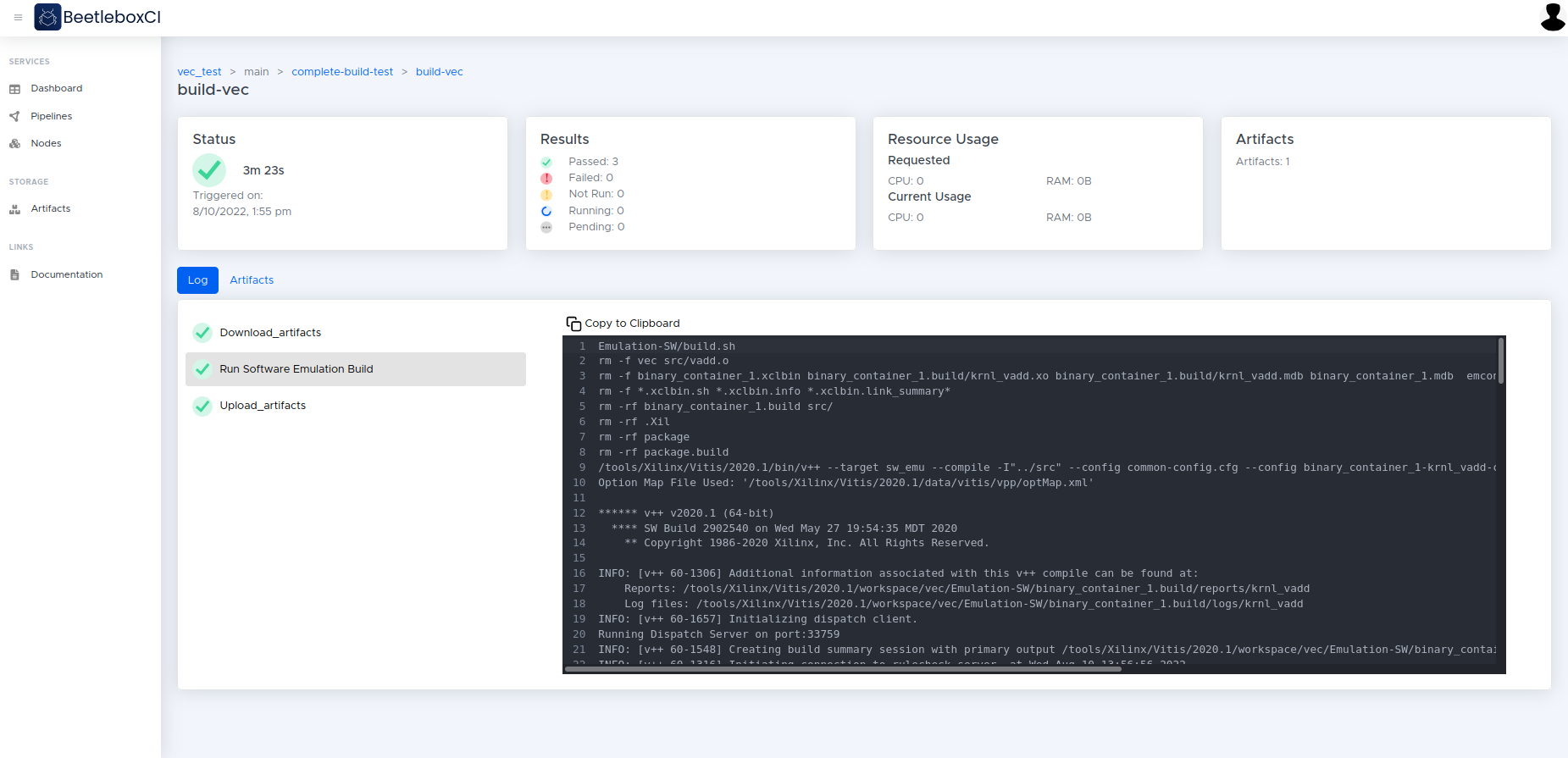
Nodes
The nodes page lists the physical and virtual machines that are part of the cluster. The status says whether the node is ready to accept jobs — if it is ready, the node is online and functioning correctly. If it is not ready, then either the node is switched off, starting up, or there is a fault. CPU is the number of CPU cores that the node offers to the cluster. There are two memory parameters: Capacity is the total memory on the node.
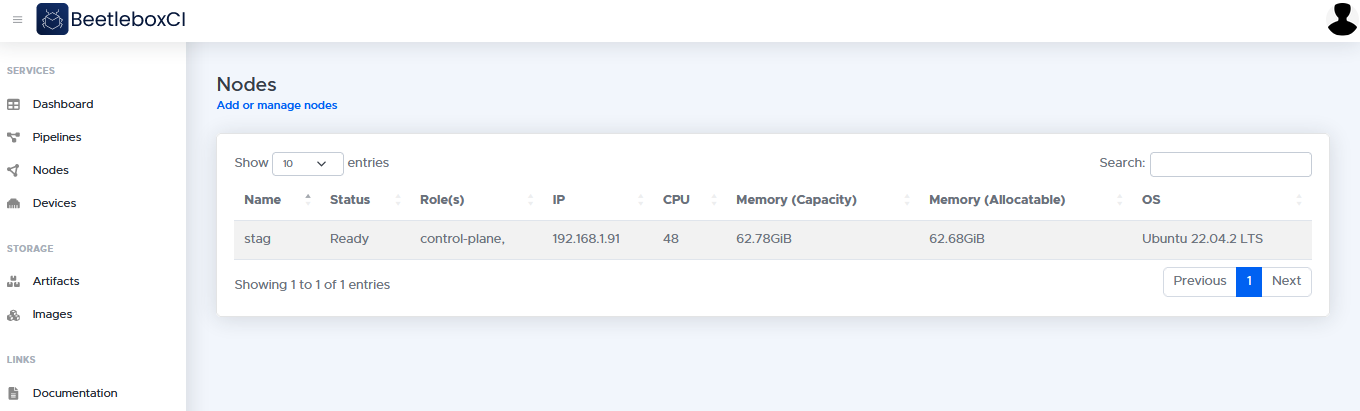
Devices
The devices page allows users to register new devices with the platform and specify commands that are used to communicate with these devices.
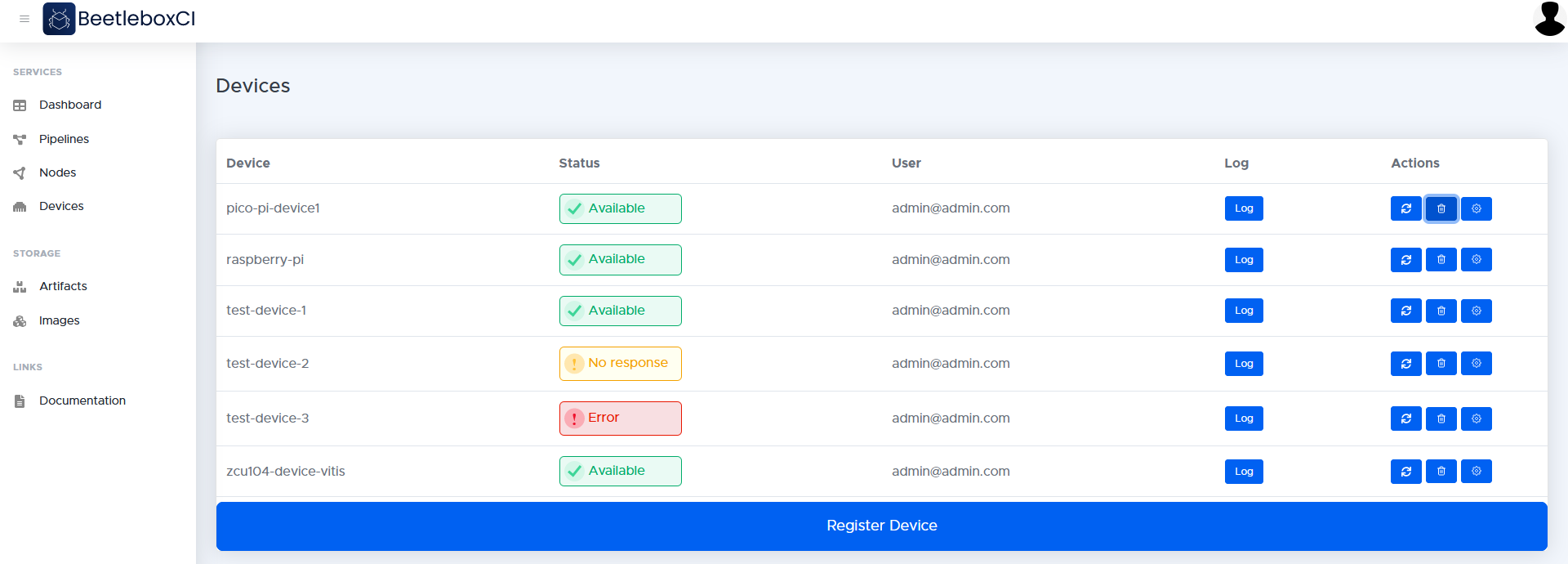
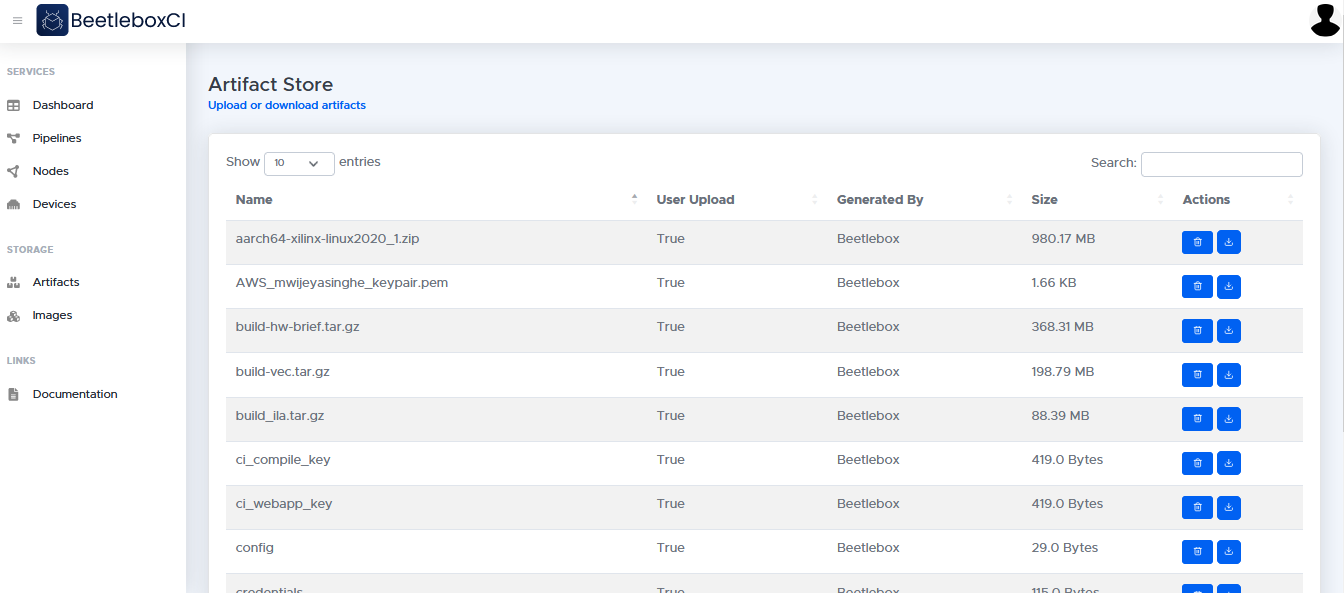
Artifact Store
The artifact store provides long-term storage for artifacts and it provides a single file source for your team. Artifacts are files or folders that have been produced by jobs or uploaded by users for use in jobs. The artifact store allows users download output files once a workflow has finished and upload files for use in workflows.
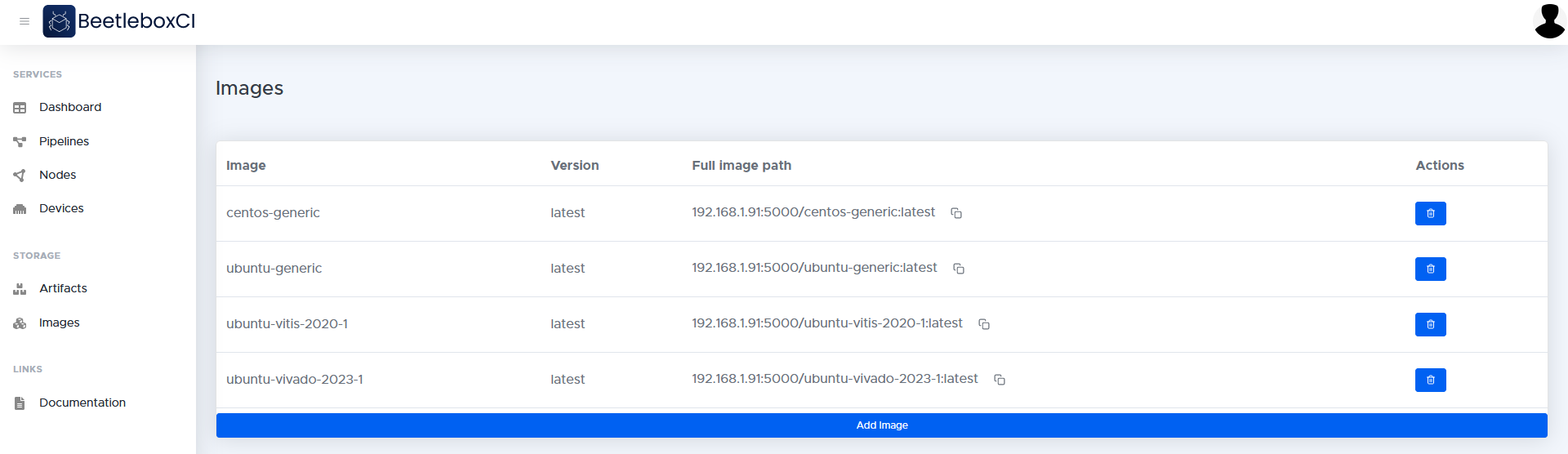
Images
The images page lists the contents of the local container registry. The images page allows users to generate scripts to pull images from remote sources and push them to the local registry. The user may also manually create and push images to the local registry using a bash terminal or other tools.
Organization settings
BeetleboxCI supports multi-tenancy, which allows multiple organisations or departments to share the same cluster and allows separation between their projects. This way, each organisation or department can have their own set of projects on a single cluster, and these will not interfere with each other.